本記事ではAmazon Forecastを利用して2020年の日経平均株価を占います。あくまで過去のチャートのみを利用した「占い」であり、「予測」「予想」とは異なる点についてご了承ください。
Amazon Forecastとは
「Amazon Forecast」とは、機械学習を用いて、時系列データから未来の値の予測をたてられるマネージドサービスです。機械学習の経験が一切なくても、時系列データさえあれば、あとはサービス側で予測を行ってくれます。
「データはあるが機械学習経験がない」という人でも、簡単に利用することができる画期的なサービスだと思います。
今回は株価の占いに利用していますが、例えば、サーバのリソース消費や、お店の売り上げデータ等の予測に利用することで、より実際的なものになると思います。
検証データ
松井証券から日経平均株価に関する日足データを取得し、ベースとして利用しています。日付の範囲は2010-01-25から2020-01-24で、指数の値は全て終値を利用し、高値、安値、出来高等のデータは利用していません。休場の日も日付を追加し、直近の値を入れています。 約110KBで3653行の小さなデータです。
サンプル(5データ)
timestamp,item_id,target_value
2010-01-25,nikkei225,10512.69
2010-01-26,nikkei225,10325.28
2010-01-27,nikkei225,10252.08
2010-01-28,nikkei225,10414.29
2010-01-29,nikkei225,10198.04
Dataset groups
まずは、予測に利用する時系列データを用意していきます。
Create dataset group
データセットの名前と、どういった種別のデータを予測するのかという選択を行います。Forecasting domainは、事前定義済みのデータセットドメインとデータセットタイプを参照して選びます。今回は株価データですが、該当するものがなかったため、Customとしています。
- Dataset group name
nikkei225
- Forecasting domain
Custom
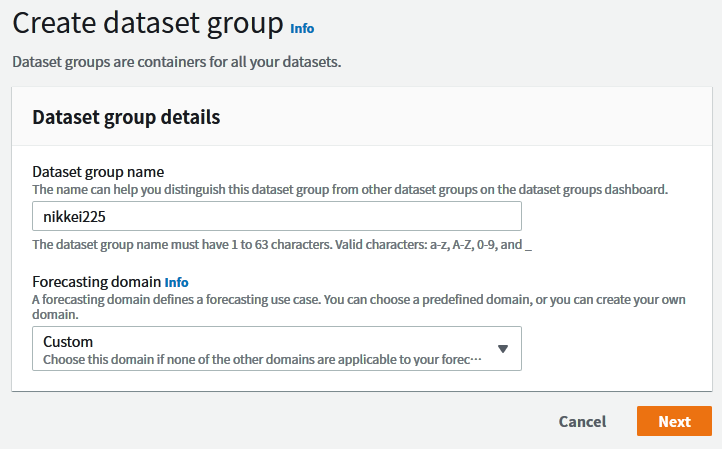
Create target time series dataset
ここで、データの頻度とデータ構造を入力します。今回は日足データを利用しているので、Frequency of your dataには1 dayを指定します。また、Data schemaではCSVファイルの列形式に合わせて定義を行っています。なお、Customドメインではtimestamp、item_id、target_value3つの指定が必須で、かつ、それらのみが含まれている状態が推奨されますので、それに従っています。
- Dataset name
nikkei225_dataset
- Frequency of your data
1 day
- Data schema
{
"Attributes": [
{
"AttributeName": "timestamp",
"AttributeType": "timestamp"
},
{
"AttributeName": "item_id",
"AttributeType": "string"
},
{
"AttributeName": "target_value",
"AttributeType": "float"
}
]
}
Import target time series data
ファイルのインポート定義です。CSVファイルは事前にS3へアップロードしておく必要があります。110KB程度なので、インポートは数分で終わりました。
- Dataset import name
nikkei225_import
- Timestamp format
yyyy-MM-dd(デフォルトはyyyy-MM-dd HH:mm:ssです)
- IAM Role
Create a new role(該当のS3ファイルにアクセス可能なIAMロールを指定します。今回は新規作成しています)
- Data location
s3://XXXXX/nikkei225.csv(CSVファイルへのフルパスを指定します)

Train a predictor
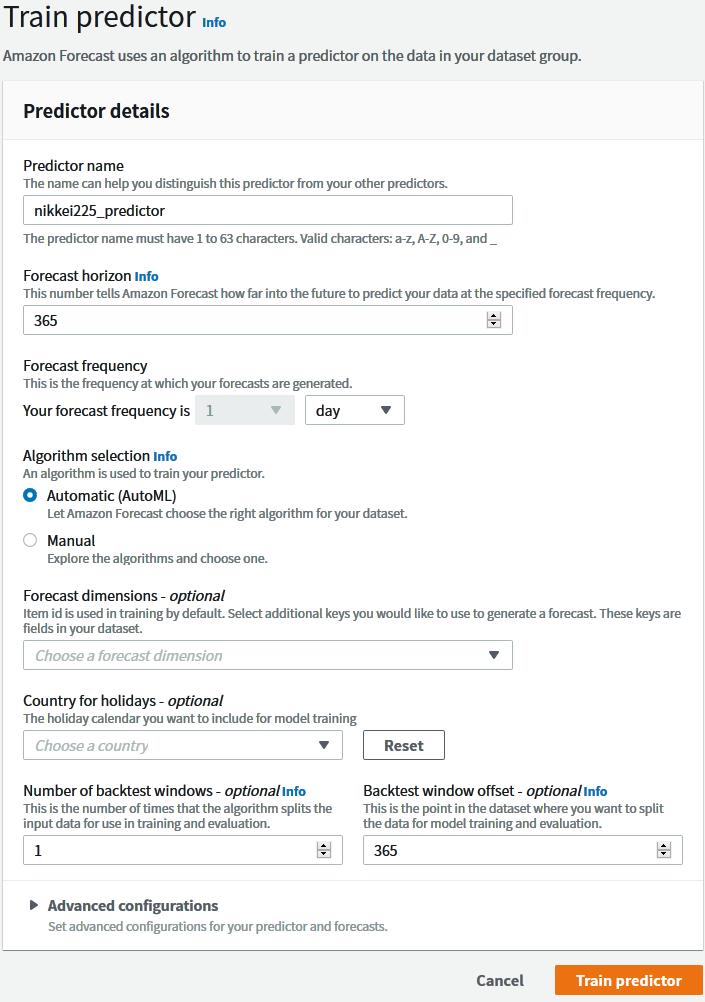
インポートが終了したら、トレーニングを設定します。 1年予想なのでForecast horizonは365にし、日足なのでForecast frequencyは1 dayにしています。
最も重要だと思われるAlgorithm selectionですが、今回は自動で選んでくれるように設定しました。「アルゴリズムとか良く分からないけど何か良い感じでお願いします」というのができてしまうのが凄いですね。結果はともかくとして。
- Predictor name
nikkei225_predictor
- Forecast horizon
365
- Forecast frequency
1 day
- Algorithm selection
Automatic (AutoML)
後はトレーニングが終わるのを待ちます。今回は3600行程度のデータですが、トレーニングに2時間30分程度かかりました。途中でPredictorを削除できないので、トレーニングを開始したら、後は終わるまで待つしかありません。
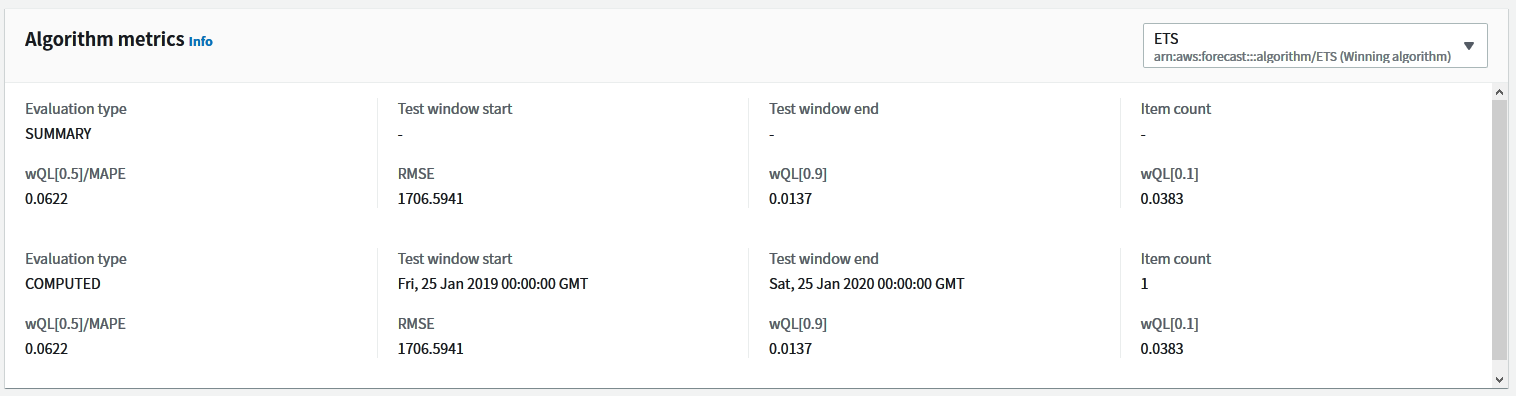
トレーニング中は終了までの見込み時間が分からないので、内心ひやひやしつつ別作業をしていると、いつの間にか終わっていたようです。今回の予測にはETS(指数平滑法)というアルゴリズムが選抜されているようでした。
Create a forecast
トレーニングが完了したら予測の作成です。先程トレーニングを行ったPredictorを用いて予測値を作成します。こちらは15分程度で完了しました。
- Forecast name
nikkei225_forecast
- Predictor
nikkei225_predictor
Forecast lookup
いよいよ、予測値を可視化して確認します。今回は2019年1月から2020年末までの値を可視化しています。
- Forecast
nikkei225_forecast
- Start date
2019/01/25 00:00:00(元データの最終日からForecast horizon分だけ前を指定できる)
- End date
2020/12/31 00:00:00( 元データの最終日からForecast horizon分だけ先を指定できる)
- Value
nikkei225(item_id列の値を指定する)
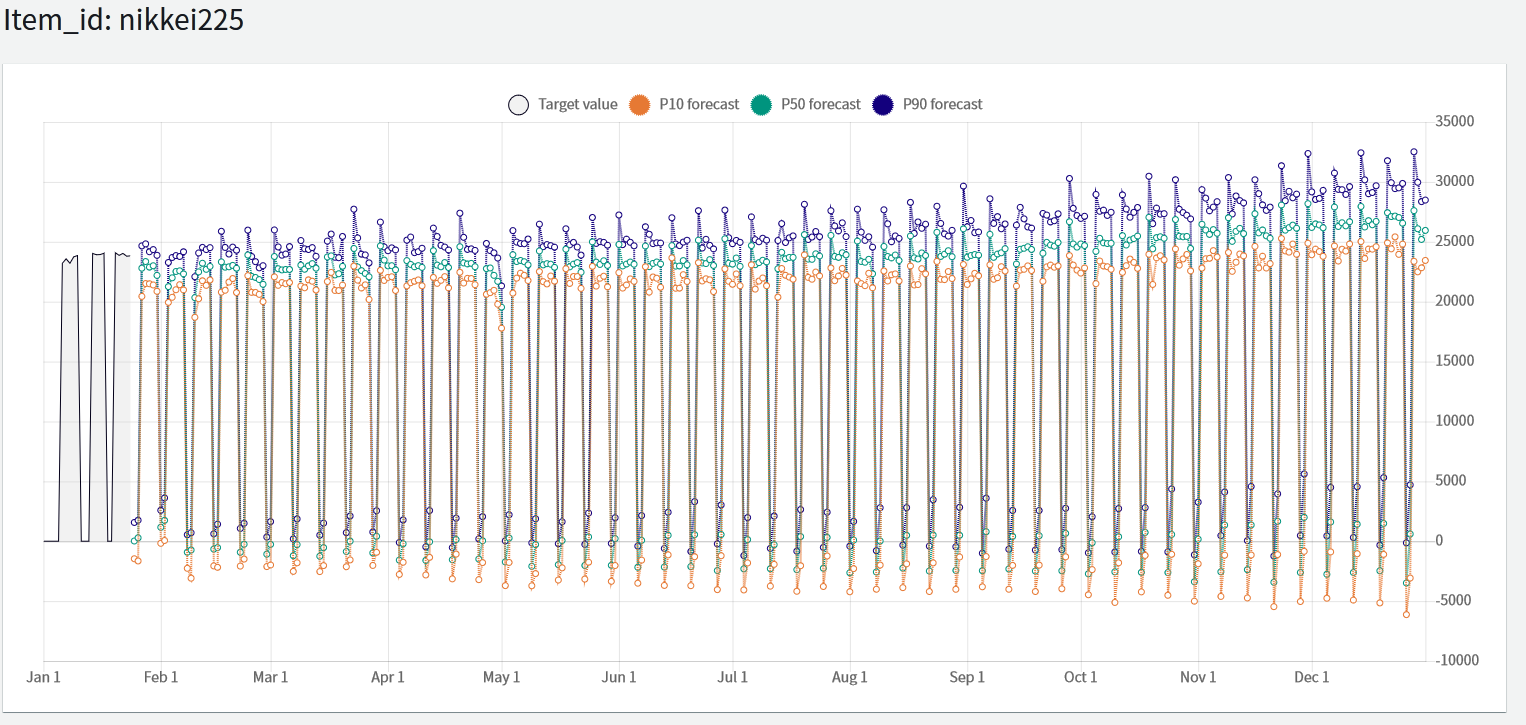
結果
チャートとは程遠い見た目の結果となりましたが、一応、日経平均株価は2020年末には19,466円~28,186円に収まる可能性が高いかもということになりそうです。
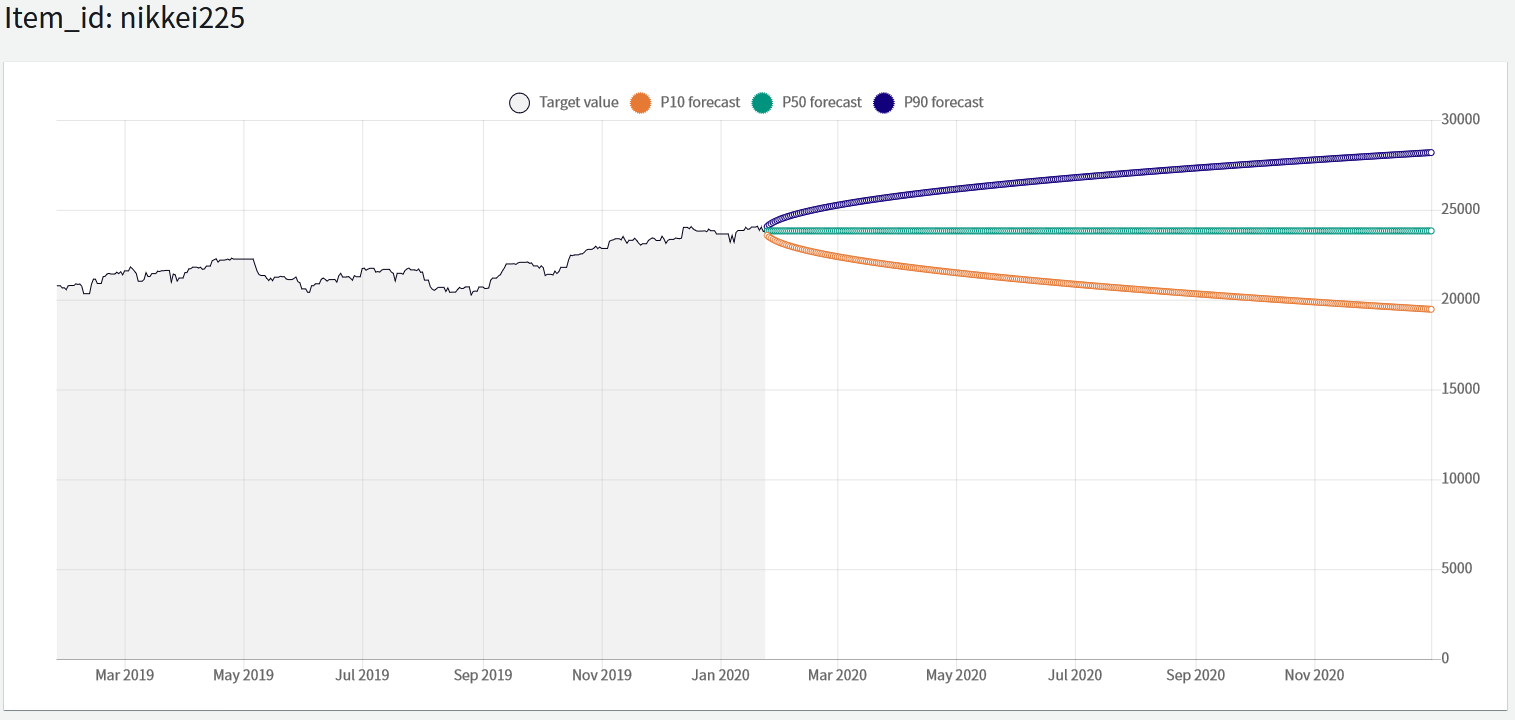
ちなみに、P10等のPは、パーセントタイルを表しています。 今回のケースで言うと、「取り得る最低値から数えて10番目」がP10で、「取り得る最低値から数えて90番目」がP90です。
参考
計測値の分布(ばらつき)を小さい数字から大きい数字に並べ変え、パーセント表示することによって、小さい数字から大きな数字に並べ変えた計測値においてどこに位置するのかを測定する単位。
詰まった点
関連する時系列データセットが欠損していると言われる
今回、関連する時系列データセットを利用しなかった理由です。本当は他の指数も利用して精度を高めたかったのですが、以下の理由からできませんでした。
結論として、関連する時系列データセットは、最小範囲としてターゲット時系列データセットの最終タイムスタンプにForecast horizonを加算した分のデータを保持している必要があるということが分かりました。
今回の例だと、ターゲット時系列データセットが2010-01-25から2020-01-24で365日の予測を行いたいので、関連する時系列データセットは最小範囲でも2010-01-25から2021-01-24の範囲のデータが必要という形です。用意する最終タイムスタンプは2020年ではなく2021年です。つまり、「未来の他指数のデータが必要」ということになります。
予測対象の日経平均株価が2010-01-25から2020-01-24となっているので、関連する時系列データも同じ範囲で用意したところ、エラーでPredictorsの生成に失敗して気が付いた形です。
エラー例
We were unable to train your predictor.
Please ensure there are no missing values for any items in the related time series, All items need data until 2021-01-23 00:00:00.0. For example, following items have missing data: item: nikkei225 only has 2127/3352 required datapoints starting 2011-11-21 00:00:00.0, please refer to documentation for additional details.
参考
関連する時系列データセットのすべての項目の最後のタイムスタンプは、ターゲット時系列の最後のタイムスタンプかつユーザー指定の予測ウィンドウ (予測期間と呼ばれる) の後である必要があります。
結果に0が混じる
今回、元々のデータには休場の株価が含まれていませんでした。これがそのまま反映されてしまい、休場ごとに値が0に落ちるというデータが出来上がってしまいました。
AWS側で世界の休日の情報を提供しているので、おそらく、どこか設定を行えば休場の値も良い感じにしてくれるのかもしれませんが(未確認)、今回は、休場の値は直近の値を利用するという形に元々のデータを変更してから学習させています。
まぁ、むしろ、こちらの方が何となくチャートらしい感じは出ているかもしれませんが。
最後に
単純に過去のチャート情報だけだと何とも判断が難しい結果となりましたが、他の要素(各国の成長率の見通しや金利の見通し等)を関連する時系列データセットに設定すれば、より、精度が高まるのではないかと思います。
今回の結果はともかくとして、専門知識を持たない一般ユーザでも、簡単に時系列データをAIに予測させられるようになるという、技術の進歩が如実に感じられるサービスでした。
アルゴリズムや関連データを検討して、いずれリベンジしたいです。